Regular Expression
Regular expressions are ubiquitous in OhMyMN. A regular expression is simply an expression that is used to match a particular formatted string.
The general search just like, if you type the word baby, it will search for all baby, including angelababy, but I only want to search for individual baby, so what should I do? Between the word and the word must be non-word characters, so we can use the regular expression \bbaby\b, \b means that one side of the location for the word characters, the other side for non-word characters.
Additional but Important
Regular expression support varies by programming language and by browser. MarginNote uses Safari JavaScriptCore engine, which does not support many features, such as the lookbehind assertion
(?<=y)x, the negative lookbehind assertion(?<!y)x.In JavaScript, there is a fixed way to write a regular expression , such as
/\bbaby\b/g, wrapped with two/. After the second slash, you can add flags to change the matching pattern, the following 5 are commonly used./xxx/gGlobal search. In the Replace() Method, all matching strings will be replaced, otherwise only the first one will be replaced./xxx/iCase-insensitive search./xxx/sAllows.to match newline characters./xxx/mAllows^and$to match newline characters./xxx/u"Unicode"; treat a pattern as a sequence of Unicode code points.
You can use Regex-Vis or iHateRegex to test and visualize。
You can use Regex Learn to get started with regular expressions by answering questions, I believe it will help you.
TIP
The contentn below is just my notes on learning regular expression. It may not be helpful to you, but if you need learn regular expression in detail, just search for regular expression on Google.
元字符
元字符是在正则表达式中具有特殊含义的符号或字符,正则表达式本质上就是通过元字符实现字符串精准匹配的。接下来,我讲的所有符号都是元字符,下面这些是简单常用的元字符。
| 符号 | 说明 |
|---|---|
. | 匹配除换行符以外的任意字符 |
\w | 匹配字母或数字或下划线 |
\s | 匹配任意的空白符 |
\d | 匹配数字 |
\b | 匹配单词的开始或结束 |
^ | 匹配字符串的开始 |
$ | 匹配字符串的结束 |
^说清楚点就是匹配每一行的开始位置, $匹配的是每一行的结尾位置。只要有了^ ,那就只会匹配每一行开头的字符串,而不会匹配每一行中间的,而$就是匹配每一行结尾的字符串,两个结合到一起,常用于单行字符串的匹配。
反义
反义一般用上面元字符的大写表示,比如\d匹配任意数字,而\D匹配除数字外的所有字符,其他的也一样。使用^来匹配除方框里给出的字符之外的所有字符。
| 符号/语法 | 说明 |
|---|---|
\W | 匹配任意不是字母,数字,下划线,汉字的字符 |
\S | 匹配任意不是空白符的字符 |
\D | 匹配任意非数字的字符 |
\B | 匹配不是单词开头或结束的位置 |
[^x] | 匹配除了 x 以外的任意字符 |
[^aeiou] | 匹配除了 aeiou 这几个字母以外的任意字符 |
限定符
限定符是跟在其他元字符后面的,用于限定元字符匹配字符的重复次数。
| 符号/语法 | 说明 |
|---|---|
* | 重复零次或更多次 |
+ | 重复一次或更多次 |
? | 重复零次或一次 |
{n} | 重复n次 |
{n,} | 重复n次或更多次 |
{n,m} | 重复n到m次 |
这部分可能不太好理解,我来举几个例子
\d+:作用是匹配由数字构成的字符串\d是匹配数字,+相当于无数个\d,数量取决于什么时候遇到非数字,必须连续。\d{1,}:作用和上面一毛一样,也是匹配由数字构成的字符串,只是可以自定义最少有几位,比如\d{3,}表示这个数字至少有三位。*相当于{0,},+相当于{1,},?相当于{0,1},后三个只是自定义程度更高,前三个使用更方便。
字符转义
当你想搜索元字符本身怎么办,那就在前面加一个\ ,比如说想搜索. ,就需要用\. 。之前说了正则表达式里所有的特殊符号都是元字符,都需要转义。
字符类
之前说的 \w ,\d ,\s 这些只能匹配任意的字母数字,而不能匹配特定的几个字母或者数字,只需要把你想匹配的装到方括号里,就像 [12345] 这样,你就能匹配到 12345 中任意一个数字了,同时你也可以用 [1-5] 表示。
除了数字,其他的字符,字母都可以这样,并且在方括号里不用担心字符转义的问题, [.*+?$] 这些都可以直接匹配。但是用于反义的 ^,我们如果想要匹配它就需要使用 [\^]。
字符、数字、字母都可以放在一起,比如[0-9A-Za-z] ,直接连在一起就行,相当于\w的效果。
举一个稍微复杂的例子,^[a-zA-Z]\w{5,17}$ ,用正则可视化我们可以看出这是一个校验密码的表达式,以字母开头,长度为6到18位。下面写的意思是再重复4到16次。用 ^$ 包在一起就表示是单独的一行。

再举一个复杂点的例子,\(?0\d{2}[) -]?\d{8},他其实能匹配四种格式的电话号码,比如 (010)88886666 或 022-22334455 或 029 12345678 或 02912345678,他们的特点在于前三位数字,有的是括号包围,有的后面跟着短横,有的后面跟着空格,有的什么都没有,这就用到了字符类,[) -] 这里面有是三种字符,包括一个空格。? 表示匹配0次或1次,所以一共四种情况。
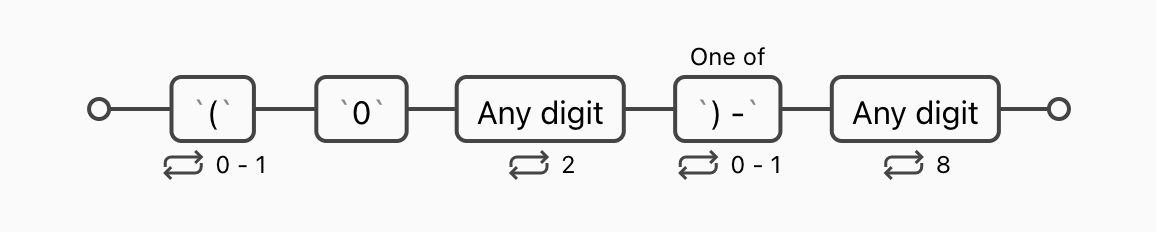
分支条件
刚才举的第二个例子,可以匹配三种格式的电话号码,但你认真思考一下就会发现,它还会匹配 010)12345678 或者 (022-87654321 这些错误的格式。因为 ? 不会进行判断,前面的字符存不存在都可以。但是我们更多的时候需要进行判断,不存在是什么格式,存在是什么格式。
拿这个例子来说,如果存在 ( ,那后面也必须是 ) ,要实现这个我们需要要用分支条件 |,这个符号就相当于取并集,两个条件满足一个即可。改写上面的表达式 \(0\d{2}\)\d{8}|0\d{2}[- ]?\d{8} 。
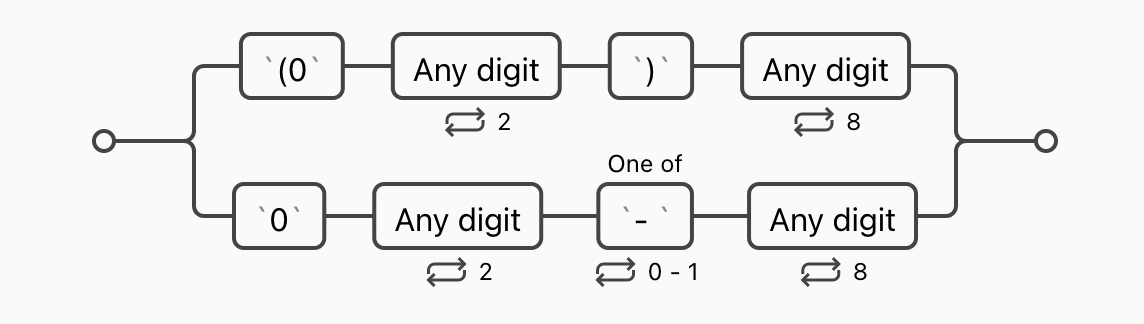
分成了两个分支,一个是有括号的,一个是没括号的。而没有括号的中间可以有一条短横,也可以没有。值得注意的是,分支条件优先匹配左边的条件,只要满足左边的条件,就不会看右边的条件了。
分组
之前说的在元字符后面加重复限定符就可以重复匹配这个字符,但是如果想重复匹配一个比较复杂的表达式呢,就需要把这个表达式放在括号 () 里面。
比如常用的 IP 地址匹配的表达式 (\d{1,3}\.){3}\d{1,3},每 3 个数字(最多 3 个)一段,共四段,中间用 . 连接。可以看做三段 3 个数字(最多 3 个)加 1 个点,最后一段为 3 个数字(最多 3 个)。
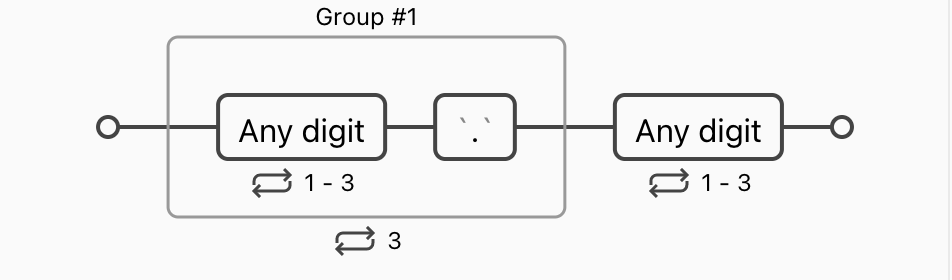
当然,这个表达式只是匹配个形式,IP 每一段有大小限制,不能大于 255,很遗憾正则表达式不能判断数字大小,所以我们只能把 3 个数字单独分开看,分为 3 个分支。
- 第一位为
2,第二位为0-4,第三位为任意数字。 - 前两位为
25,第三位0-5。 - 第一位为
0或1或者为空,第二位为任意数字,第三位为空或任意数字。
然后将这3个数字的表达式分为一组即可。IP 地址完整匹配表达式
((2[0-4]\d|25[0-5]|[01]?\d\d?)\.){3}(2[0-4]\d|25[0-5]|[01]?\d\d?)
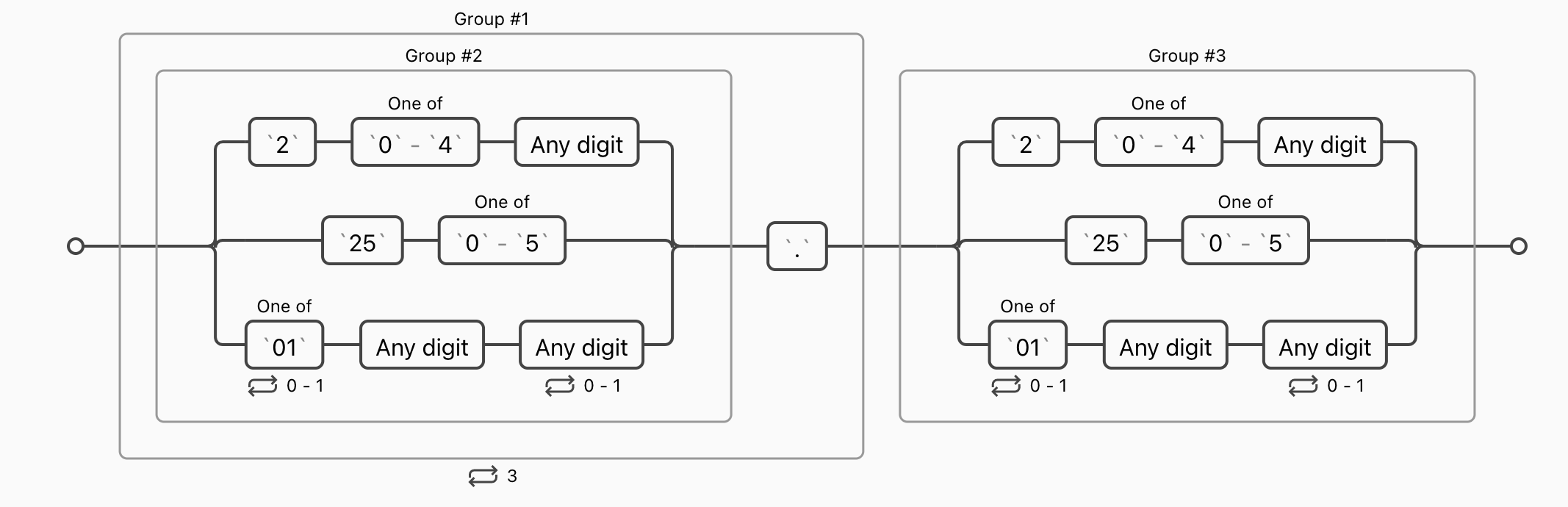
1. 捕获组
默认 () 就是捕获组,会将括号里匹配到的内容保存到内存中,你可以使用 \1 来引用它,当然,只能在括号后引用,这就是 后向引用。
捕获组在 Replace() Method 中非常有用。可以使用 $1 来引用捕获的内容。
2. 非捕获组
如果只是想分组,其实不需要用捕获组,可以使用 (?:) 来分组。
在 Split() Method 中,如果使用捕获组,捕获的内容包括在结果中,会增加不确定性,一般就是用的非捕获组。
贪婪与懒惰
这其实是很多人不太明白,但却非常重要的知识点。
什么是贪婪,举个例子,如果一个字符串 1010000000001 ,我们需要匹配 101 一般人就会使用 1\d+1 ,但是这样你会匹配到 1010000000001 这整个字符串,这就是贪婪匹配,他会尽可能多的匹配字符。
而如果想匹配到 101 ,我们就需要使用 1\d+?1 ,在重复限定符后加一个 ? ,就变成了懒惰匹配,会尽可能少的匹配。尽可能少重复,遇到第一个满足条件的就停止匹配。? 本身就是重复限定符,表示重复 0 次或 1 次,所以也有 .?? 这种形式,至于这有什么作用,我也不知道。
零宽断言
可谓是正则里面最厉害的,可惜的是 MarginNote 的 JS 引擎对它的支持度不高。它不匹配任何字符串,只匹配一个位置,比如 \b ^ $ 这些都是断言。
零宽好理解,匹配的只是一个位置,本身是没有宽度的。而断言,在调试代码中很常用,表示我断定这个条件是满足的,如果不满足就是出 bug 了。至于在这里嘛,可能就是断定这个位置的意思。
零宽断言有很多中别名,比如 环视,分为了 肯定逆序环视、否定逆序环视、肯定顺序环视、否定顺序环视。
这里我一般常用:
- 向前断言
x(?=y),给出了一个位置,表示 y 的前面,所以我们匹配的就是在 y 前面的 x。也就说匹配的 x 必须有 y 跟在后面。注意断言只是一个位置,他不会被包含着匹配结果中。 - 向前否定断言
x(?!y)顾名思义,给出的位置是一个字符的前面,但不是 y,匹配的是没有 y 跟在后面的 x。 向后断言(?<=y)x匹配的是有 y 在前面的 x。不支持向后否定断言(?<!y)x匹配的是没有 y 在前面的 x。不支持